
The CUDA LATCH Binary Descriptor: Because Sometimes Faster Means Better
Published in Workshop on Local Features: State of the art, open problems and performance evaluation, at the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 2016
Recommended citation: Christopher Parker, Matthew Daiter, Kareem Omar, Gil Levi and Tal Hassner. The CUDA LATCH Binary Descriptor: Because Sometimes Faster Means Better. Workshop on Local Features: State of the art, open problems and performance evaluation, at the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 2016.
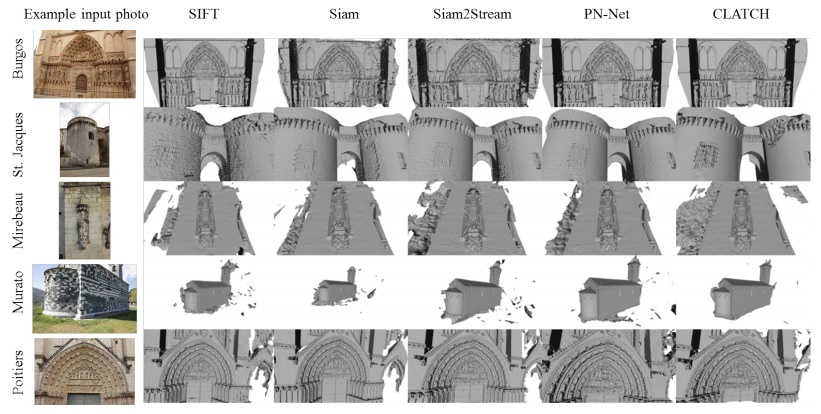
Qualitative SfM reconstructions. Results showing the output of the same SfM pipeline on five of the eights scenes from [23], comparing the use of SIFT, Siam and Siam2Stream from, PN-Net and our CLATCH. These results show only minor differences in output 3D shapes, despite the substantial difference in run time required for the different representations
Abstract
Accuracy, descriptor size, and the time required for extraction and matching are all important factors when selecting local image descriptors. To optimize over all these requirements, this paper presents a CUDA port for the recent Learned Arrangement of Three Patches (LATCH) binary descriptors to the GPU platform. The design of LATCH makes it well suited for GPU processing. Owing to its small size and binary nature, the GPU can further be used to efficiently match LATCH features. Taken together, this leads to breakneck descriptor extraction and matching speeds. We evaluate the trade off between these speeds and the quality of results in a feature matching intensive application. To this end, we use our proposed CUDA LATCH (CLATCH) to recover structure from motion (SfM), comparing 3D reconstructions and speed using different representations. Our results show that CLATCH provides high quality 3D reconstructions at fractions of the time required by other representations, with little, if any, loss of reconstruction quality.