
OCR-Free Transcript Alignment
Published in International Conference on Document Analysis and Recognition (ICDAR), Washington DC, 2013
Recommended citation: Tal Hassner, Lior Wolf, and Nachum Dershowitz. OCR-Free Transcript Alignment. International Conference on Document Analysis and Recognition (ICDAR), Washington DC, 2013.
Abstract
Recent large-scale digitization and preservation efforts have made images of original manuscripts, accompanied by transcripts, commonly available. An important challenge, for which no practical system exists, is that of aligning transcript letters to their coordinates in manuscript images. Here we propose a system that directly matches the image of a historical text with a synthetic image created from the transcript for the purpose. This, rather than attempting to recognize individual letters in the manuscript image using optical character recognition (OCR). Our method matches the pixels of the two images by employing a dedicated dense flow mechanism coupled with novel local image descriptors designed to spatially integrate local patch similarities. Matching these pixel representations is performed using a message passing algorithm. The various stages of our method make it robust with respect to document degradation, to variations between script styles and to non-linear image transformations. Robustness, as well as practicality of the system, are verified by comprehensive empirical experiments.
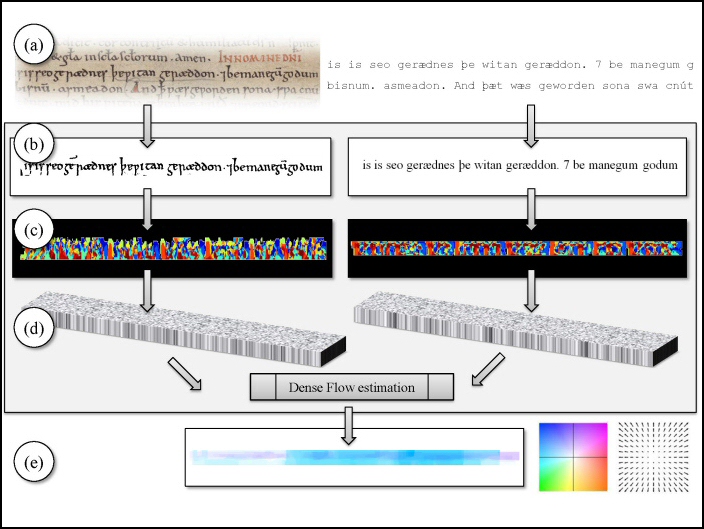
The stages of the proposed dense-flow method. (a) Our input is a historical manuscript image, along with a line-by-line transcript of the text. (b, left) Each manuscript line is binarized, horizontally projected and trimmed; (b, right) the matching transcript line is rendered using an appropriate font to produce a matching reference image. (c) FPLBP codes [Wolf, Hassner, and Taigman, ECCVw, 2008] are produced for the two images (shown color coded). (d) Each pixel is represented by a 16-valued, weighted histogram of the FPLBP codes in its elongated neighborhood. A SIFT flow [Liu, Yuen, and Torralba, TPAMI 2011] variant is then applied to form dense correspondences between these representations in the two views. (e) The output flow (color coded) assigns a matching pixel from the rendered image, along with its known character label, to each pixel in the manuscript line image.