
Motion Interchange Patterns for Action Recognition in Unconstrained Videos
Published in European Conference on Computer Vision (ECCV), Firenze , Italy, 2012
Recommended citation: Orit Kliper-Gross, Yaron Gurovich, Tal Hassner.Motion Interchange Patterns for Action Recognition in Unconstrained Videos. European Conference on Computer Vision (ECCV), Firenze , Italy, 2012.
Abstract
Action Recognition in videos is an active research field that is fueled by an acute need, spanning several application domains. Still, existing systems fall short of the applications’ needs in real-world scenarios, where the quality of the video is less than optimal and the viewpoint is uncontrolled and often not static. In this paper, we consider the key elements of motion encoding and focus on capturing local changes in motion directions. In addition, we decouple image edges from motion edges using a suppression mechanism, and compensate for global camera motion by using an especially fitted registration scheme. Combined with a standard bag-of-words technique, our methods achieves state-of-the-art performance in the most recent and challenging benchmarks.
Related projects
The Action Similarity Labeling Challenge (ASLAN)
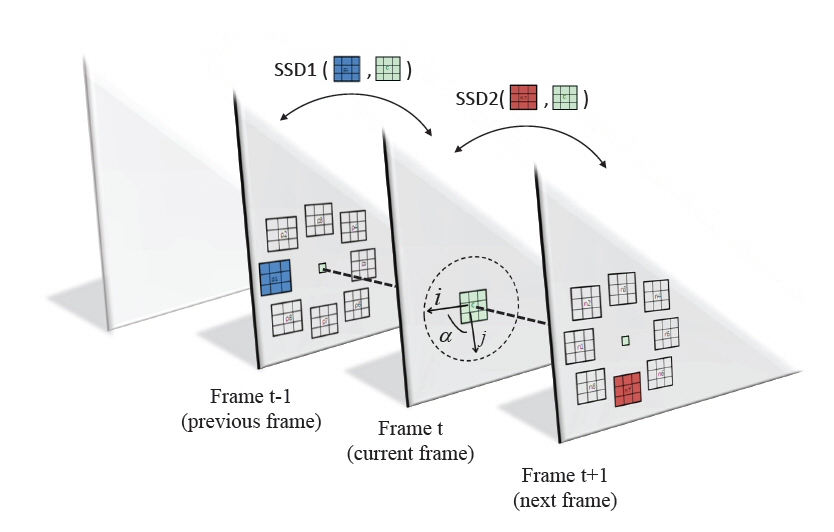 |  |
|---|---|
| (a) | (b) |
The Motion Interchange Patterns (MIP) representation. (a) Our encoding is based on comparing two SSD scores computed between three patches from three consecutive frames. Relative to the location of the patch in the current frame, the location of the patch in the previous (next) frame is said to be in direction i (j); The angle between directions i and j is denoted alpha. (b) Illustrating the different motion patterns captured by different i and j values. Blue arrows represent motion from a patch in position i in the previous frame; red for the motion to the patch j in the next frame. Shaded diagonal strips indicate same alpha values.
Results
Below are some results of the MIP representation, applied to recent Action Recognition benchmarks. For additional results and more details, please see the paper.
| System | No CSML | With CSML | ||
| Accuracy | AUC | Accuracy | AUC | |
| LTP [Yeffet & Wolf 09] | 55.45 +- 0.6% | 57.2 | 58.50 +- 0.7% | 62.4 |
| HOG [Laptev et al. 08] | 58.55 +- 0.8% | 61.59 | 60.15 +- 0.6% | 64.2 |
| HOF [Laptev et al. 08] | 56.82 +- 0.6% | 58.56 | 58.62 +- 1.0% | 61.8 |
| HNF [Laptev et al. 08] | 58.67 +- 0.9% | 62.16 | 57.20 +- 0.8% | 60.5 |
| MIP single channel alpha=0 | 58.27 +- 0.6% | 61.7 | 61.52 +- 0.8% | 66.5 |
| MIP single best channel alpha=1 | 61.45 +- 0.8% | 66.1 | 63.55 +- 0.8% | 69.0 |
| MIP w/o suppression | 61.67 +- 0.9% | 66.4 | 63.17 +- 1.1% | 68.4 |
| MIP w/o motion compensation | 62.27 +- 0.8% | 66.4 | 63.57 +- 1.0% | 69.5 |
| MIP w/o both | 60.43 +- 1.0% | 64.8 | 63.08 +- 0.9% | 68.2 |
| MIP on stabilized clips | 59.73 +- 0.77% | 62.9 | 62.30 +- 0.77% | 66.4 |
| MIP | 62.23 +- 0.8% | 67.5 | 64.62 +- 0.8% | 70.4 |
| HOG+HOF+HNF | 60.88 +- 0.8% | 65.3 | 63.12 +- 0.9% | 68.0 |
| HOG+HOF+HNF with OSSML [Kliper-Gross et al. 11] | 62.52 +- 0.8% | 66.6 | 64.25 +- 0.7% | 69.1 |
| MIP+HOG+HOF+HNF | 64.27 +- 1.0% | 69.2 | 65.45 +- 0.8% | 71.92 |
Table 1. Comparison to previous results on the ASLAN benchmark. The average accuracy and standard error on the ASLAN benchmark is given for a list of methods (see text for details). All HOG, HOF, and HNF results are taken from [Kliper-Gross et al. 11, Kliper-Gross et al. 12].
| System | Original clips | Stabilized clips |
| HOG/HOF [Laptev et al. 08] | 20.44% | 21.96% |
| C2 [Jhuang et al. 07] | 22.83% | 23.18% |
| Action Bank [Sadanand & Corso 12] | 26.90% | N/A |
| MIP | 29.17% | N/A |
Table 2. Comparison to previous results on the HMDB51 database. Since our method contains a motion compensation component, we tested our method on the more challenging unstabilized videos. Our method significantly outperforms the best results obtained by previous work.
| System | Splits clips | LOgO |
| HOG/HOF [Laptev et al. 08] | 47.9% | N/A |
| Action Bank [Sadanand & Corso 12] | 57.9% | N/A |
| MIP | 68.51% | 72.68% |
Table 3. Comparison to previous results on the UCF50 database. Our method significantly outperforms all reported methods.
MIP video descriptor for action recognition - Code
MATLAB code for computing the Motion Interchange Patterns (MIP) video descriptor is now available for download here. Please see the ReadMe.txt for information on how to install and run the code.
If you use this code in your own work, please cite our paper.
Copyright and disclaimer
Copyright 2012, Orit Kliper-Gross, Yaron Gurovich, Tal Hassner, and Lior Wolf