
What Does the Scene Look Like from a Scene Point?
Published in European Conference on Computer Vision (ECCV), 2002
Recommended citation: Michal Irani, Tal Hassner, and P.Anandan. What Does the Scene Look Like from a Scene Point? European Conference on Computer Vision (ECCV), 2002
Abstract
In this paper we examine the problem of synthesizing virtual views from scene points within the scene, i.e., from scene points which are imaged by the real cameras. On one hand this provides a simple way of defining the position of the virtual camera in an uncalibrated setting. On the other hand, it implies extreme changes in viewpoint between the virtual and real cameras. Such extreme changes in viewpoint are not typical of most New-View-Synthesis (NVS) problems. In our algorithm the virtual view is obtained by aligning and comparing all the pro jections of each line-of-sight emerging from the “virtual camera” center in the input views. In contrast to most previous NVS algorithms, our approach does not require prior correspondence estimation nor any explicit 3D reconstruction. It can handle any number of input images while simultaneously using the information from all of them. How- ever, very few images are usually enough to provide reasonable synthesis quality. We show results on real images as well as synthetic images with ground-truth
Some Results
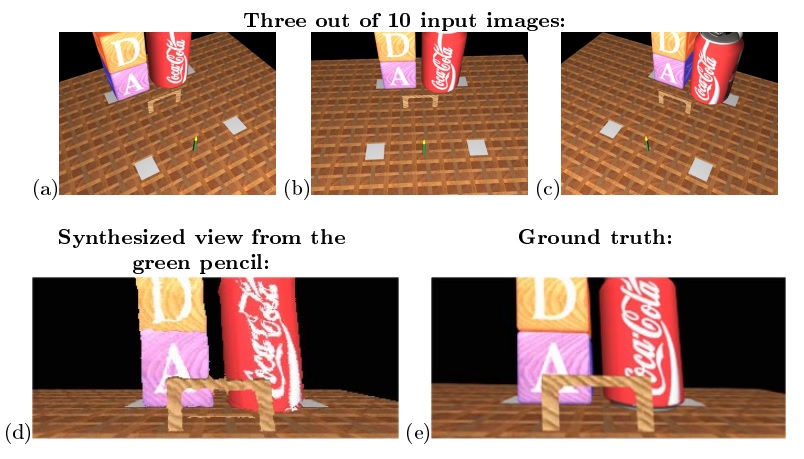
Synthesis results for the Coke-Can sequence. Images a-c were rendered from a 3D graphic model. These images were used to synthesize a view of the scene from the tip of the green pencil standing on the floor, looking in the direction of the wooden gate. The synthesized view is shown in figure d. Figure e shows the ground truth image rendered directly from the 3D model from the same viewpoint. This shows the geometric correctness of our synthesis.
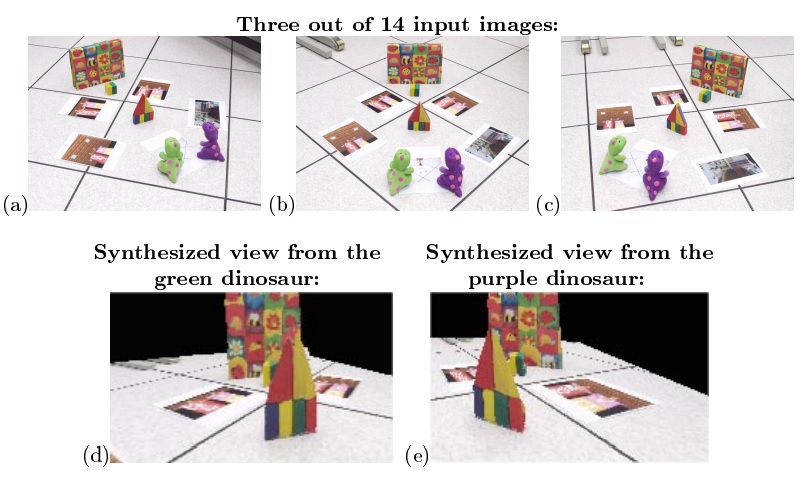
Synthesis results for the Folder sequence. The result of applying our algorithm to images of a real scene captured by an off the shelf digital camera. The algorithm was used to synthesize virtual views of the scene from two different scene points: Figure d shows a reconstructed view of the scene from the tip of the green dinosaur’s nose using all 14 input images. Figure e shows the reconstructed view of the scene from the tip of the purple dinosaur’s nose created using only 11 of the input images.