
A Piggyback Representation for Action Recognition
Published in IEEE International Workshop on Deep-Vision, at the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, 2014
Recommended citation: Lior Wolf, Yair Hanani, Tal Hassner. A Piggyback Representation for Action Recognition. IEEE International Workshop on Deep-Vision, at the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, 2014
Abstract
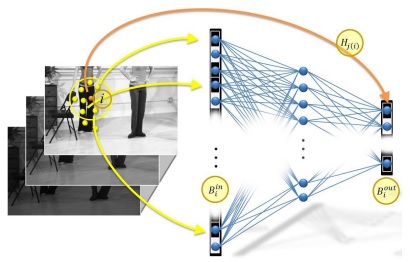
In video understanding, the spatial patterns formed by local space-time interest points hold discriminative information. We encode these spatial regularities using a word2vec neural network, a recently proposed tool in the field of text processing. Then, building upon recent accumulator based image representation solutions, input videos are represented in a hybrid manner: the appearance of local space time interest points is used to collect and associate the learned descriptors, which capture the spatial patterns. Promising results are shown on recent action recognition benchmarks, using well established methods as the underlying appearance descriptors.